За последние несколько месяцев руководители технологических компаний, такие как Илон Маск, хвалили эффективность моделей искусственного интеллекта своих компаний на конкретном бенчмарке – Chatbot Arena. Этот проект, поддерживаемый некоммерческой организацией LMSYS, стал чем-то вроде одержимости отрасли фанатов ИИ. Посты об обновлениях в таблицах лидеров моделей собирают сотни просмотров и репостов на Reddit и X, а официальный аккаунт LMSYS X насчитывает более 54 000 подписчиков. Только за последний год сайт организации посетили миллионы людей. Тем не менее, остаются некоторые вопросы относительно способности Chatbot Arena продемонстрировать нам, насколько «хороши» используемые модели на самом деле.
Что такое Chatbot Arena?
Chatbot Arena — это опенсорсный проект, который позволяет пользователям сравнивать различные модели искусственного интеллекта, оценивая их результаты в режиме реального времени. На платформе пользователи могут выбирать две модели для тестирования и предоставлять свои оценки, что способствует объективному анализу их производительности. Недавно в Chatbot Arena появилась модель gpt2-chatbot, которая, по мнению тестировщиков, превзошла GPT-4 и другие современные модели, что вызвало активные обсуждения в сообществе.

В поисках нового ориентира
Прежде чем углубляться, давайте на минутку разберемся, что такое LMSYS и как компания стала настолько популярной. Начнем с того, что некоммерческая организация была запущена только в апреле прошлого года как проект, возглавляемый студентами и преподавателями Carnegie Mellon, UC Berkeley’s SkyLab и UC San Diego. Некоторые из основателей теперь работают в Google DeepMind, xAI Маска и Nvidia. По сути, сегодня LMSYS в основном управляется исследователями, связанными со SkyLab.
LMSYS не ставила перед собой задачу создания вирусной таблицы лидеров моделей. Миссия основания группы заключалась в том, чтобы сделать модели (в частности, генеративные модели в духе OpenAI ChatGPT) более доступными путем их совместной разработки и предоставления открытого исходного кода. Но вскоре после основания LMSYS ее исследователи, недовольные состоянием бенчмаркинга ИИ, увидели ценность в создании собственного инструмента тестирования.
«Текущие бенчмарки не в состоянии адекватно удовлетворить потребности современных моделей, особенно в оценке предпочтений пользователей», — написали исследователи в технической статье, опубликованной в марте. «Таким образом, существует настоятельная необходимость в открытой, живой платформе оценки, основанной на человеческих предпочтениях, которая может более точно отражать реальное использование».
На самом деле наиболее часто используемые сегодня бенчмарки плохо справляются с задачей понимания того, как среднестатистический человек взаимодействует с моделями. Многие из навыков, которые проверяют бенчмарки, например, решение математических задач уровня доктора философии, редко будут актуальны для большинства людей, использующих, скажем, Claude.
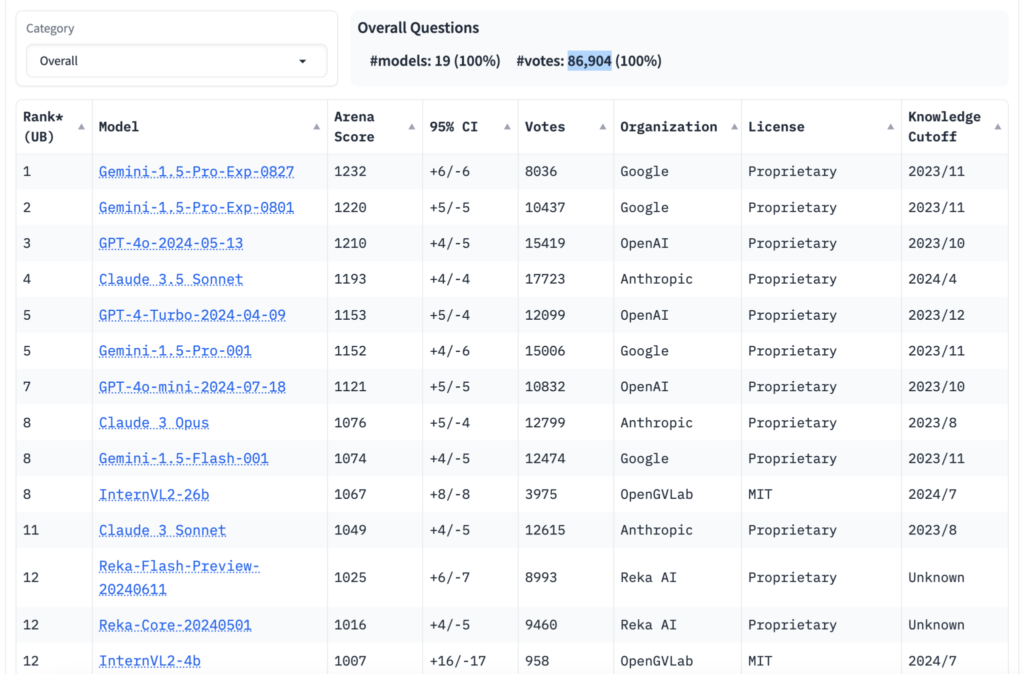
Создатели LMSYS чувствовали то же самое, и поэтому они разработали альтернативу – Chatbot Arena. Это некий краудсорсинговый тест, предназначенный для учета «тонких» аспектов моделей и их производительности при решении открытых реальных задач.
Принцип работы платформы
Chatbot Arena позволяет любому человеку в сети задать вопрос (или вопросы) двум случайно выбранным анонимным моделям. Как только человек соглашается с ToS, позволяющим использовать его данные для будущих исследований, он может проголосовать за предпочтительные ответы из двух соревнующихся моделей, после чего раскрываются личности моделей. Он также может объявить ничью или сказать «обе плохие».
«Вооружившись этими данными, мы применяем набор мощных статистических методов для оценки рейтинга по моделям максимально надежно и эффективно для выборки», — пояснили разработчики.
С момента запуска Chatbot Arena компания LMSYS добавила десятки открытых моделей в свой инструмент тестирования и сотрудничала с такими университетами, как Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), а также с такими компаниями, как OpenAI, Google, Anthropic, Microsoft, Meta, Mistral и Hugging Face. И все это для того, чтобы сделать их модели доступными для тестирования. Chatbot Arena теперь включает более 100 моделей, включая мультимодальные модели (модели, которые могут понимать данные, выходящие за рамки простого текста), такие как GPT-4o от OpenAI и Claude 3.5 Sonnet от Anthropic.
Таким образом было отправлено и оценено более миллиона вопросов и пар ответов, что позволило получить огромный массив данных для ранжирования.
Предвзятость и отсутствие прозрачности
В мартовской статье основатели LMSYS утверждают, что вопросы, задаваемые пользователями Chatbot Arena, «достаточно разнообразны», чтобы служить эталоном для ряда вариантов использования ИИ.
«Благодаря своей уникальной ценности и открытости Chatbot Arena стала одной из самых упоминаемых таблиц лидеров моделей», — пишут они.
Но насколько информативны результаты на самом деле? Это актуальный вопрос для обсуждения. Ючен Линь, научный сотрудник некоммерческого Института Аллена по ИИ, говорит, что LMSYS не была полностью прозрачна в отношении возможностей модели, знаний и навыков, которые она оценивает на своей платформе. В марте LMSYS выпустила набор данных LMSYS-Chat-1M, содержащий миллион разговоров между пользователями и 25 моделями на Chatbot Arena. Но с тех пор набор данных не обновлялся.
«Оценка невоспроизводима, а ограниченность данных, опубликованных LMSYS, затрудняет глубокое изучение ограничений моделей», — сказал Линь.
Что касается того, насколько подробно LMSYS описала свой подход к тестированию, ее исследователи в мартовской статье заявили, что они используют «эффективные алгоритмы выборки», чтобы сопоставлять модели друг с другом «таким образом, который ускоряет сходимость рейтингов, сохраняя при этом статистическую достоверность». Они написали, что LMSYS собирает около 8000 голосов за модель, прежде чем обновляет рейтинги Chatbot Arena, и этот порог обычно достигается через несколько дней.

Но Линь считает, что голосование не учитывает способность (или неспособность) людей определять галлюцинации по моделям, а также различия в их предпочтениях, что делает их голоса ненадежными. Например, некоторым пользователям могут понравиться более длинные ответы в стиле markdown, в то время как другим могут понравиться более краткие ответы. В результате два пользователя могут дать противоположные ответы на одну и ту же пару ответов, и оба будут одинаково верными, но это ставит под сомнение ценность подхода в корне. Только недавно LMSYS экспериментировала с контролем «стиля» и «содержания» ответов моделей в Chatbot Arena.
«Собранные данные о человеческих предпочтениях не учитывают эти тонкие предубеждения, и платформа не различает «A значительно лучше, чем B» и «A лишь немного лучше, чем B», — сказал Линь. «Хотя постобработка может смягчить некоторые из этих предубеждений, необработанные данные о человеческих предпочтениях остаются зашумленными».
Майк Кук, научный сотрудник Лондонского университета королевы Марии, специализирующийся на ИИ и игровом дизайне, согласился с оценкой Лин.
«Вы могли бы запустить Chatbot Arena еще в 1998 году и все равно говорить о резких изменениях рейтинга или крупных мощных чат-ботах, но они были бы ужасны», — добавил он, отметив, что, хотя Chatbot Arena и оформлена как эмпирический тест, она представляет собой относительную оценку моделей.
Более проблемной предвзятостью, нависшей над Chatbot Arena, является текущий состав ее пользовательской базы. Поскольку бенчмарк стал популярен исключительно благодаря сарафанному радио в кругах ИИ и технологической индустрии, вряд ли он привлек очень представительную аудиторию, говорит Лин. Подтверждая его теорию, главные вопросы в наборе данных LMSYS-Chat-1M относятся к программированию, инструментам ИИ, ошибкам и исправлениям программного обеспечения и дизайну приложений.
«Распределение данных тестирования может неточно отражать реальных пользователей-людей целевого рынка», — сказал Линь. «Более того, процесс оценки платформы в значительной степени неконтролируемый, полагаясь в первую очередь на постобработку для маркировки каждого запроса различными тегами, которые затем используются для разработки рейтингов, специфичных для задач. Такому подходу не хватает систематической строгости, что затрудняет оценку сложных вопросов рассуждения исключительно на основе человеческих предпочтений».
Кук отметил, что поскольку пользователи Chatbot Arena выбирают сами, то в первую очередь они заинтересованы в тестировании моделей, поэтому они могут быть менее заинтересованы в стресс-тестировании или доведении моделей до предела своих возможностей.
«Это не лучший способ проводить исследование в целом», — сказал Кук. «Оценщики задают вопрос и голосуют за то, какая модель «лучше», но «лучше» на самом деле нигде не определено LMSYS. Достижение действительно хороших результатов в этом бенчмарке может заставить людей думать, что победивший чат-бот на основе ИИ более человечен, более точен, более безопасен, более надежен и так далее, но на самом деле это не означает ничего из этого».
LMSYS пытается сбалансировать эти предубеждения, используя автоматизированные системы — MT-Bench и Arena-Hard-Auto, которые используют сами модели (GPT-4 и GPT-4 Turbo от OpenAI) для ранжирования качества ответов других моделей. Хотя LMSYS утверждает, что модели «хорошо соответствуют как контролируемым, так и краудсорсинговым человеческим предпочтениям», вопрос еще далек от разрешения.
Коммерческие связи и обмен данными
Лин говорит, что растущие коммерческие связи LMSYS — еще одна причина относиться к рейтингу с долей скепсиса. Некоторые поставщики, такие как OpenAI, которые обслуживают свои модели через API, имеют доступ к данным об использовании моделей, которые они могли бы использовать, чтобы по сути «обучить тесту», если бы захотели. Это делает процесс тестирования потенциально несправедливым для открытых, статических моделей, работающих в собственном облаке LMSYS.
«Компании могут постоянно оптимизировать свои модели, чтобы лучше соответствовать распределению пользователей LMSYS, что может привести к недобросовестной конкуренции и менее значимой оценке», — добавил Линь. «Коммерческие модели, подключенные через API, могут получать доступ ко всем входным данным пользователей, что дает компаниям с большим трафиком преимущество».
Кук добавил: «Вместо того чтобы поощрять новые исследования в области ИИ или что-то в этом роде, LMSYS поощряет разработчиков подстраивать мелкие детали, чтобы получить преимущество в формулировках перед конкурентами».
А еще LMSYS также частично спонсируется организациями, одной из которых является венчурная фирма, активно участвующая в гонке за ИИ. В общем, не все так однозначно, как казалось изначально. Есть много сомнений в достоверности тестирования разных моделей и в результатах их оценки. Поэтому к рейтингам Chatbot Arena нужно подходить максимально осторожно, понимая, что там сейчас идет борьба за первые позиции между лидерами рынка, которые готовы идти на разные ухищрения, чтобы хоть на подобных платформах казаться лидерами.

